HOTSPOT -
You have an Azure Data Lake Storage Gen2 container.
Data is ingested into the container, and then transformed by a data integration application. The data is NOT modified after that. Users can read files in the container but cannot modify the files.
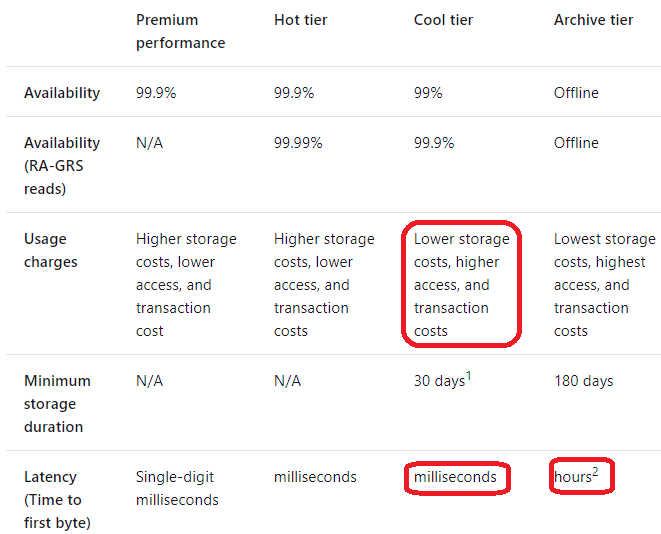
You need to design a data archiving solution that meets the following requirements:
✑ New data is accessed frequently and must be available as quickly as possible.
✑ Data that is older than five years is accessed infrequently but must be available within one second when requested.
✑ Data that is older than seven years is NOT accessed. After seven years, the data must be persisted at the lowest cost possible.
✑ Costs must be minimized while maintaining the required availability.
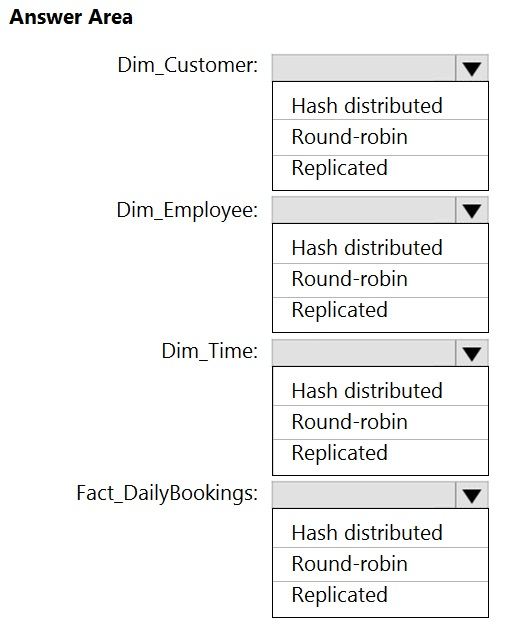
How should you manage the data? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point
Hot Area: