A Data Engineer is investigating a query that is taking a long time to return. The Query Profile shows the following:
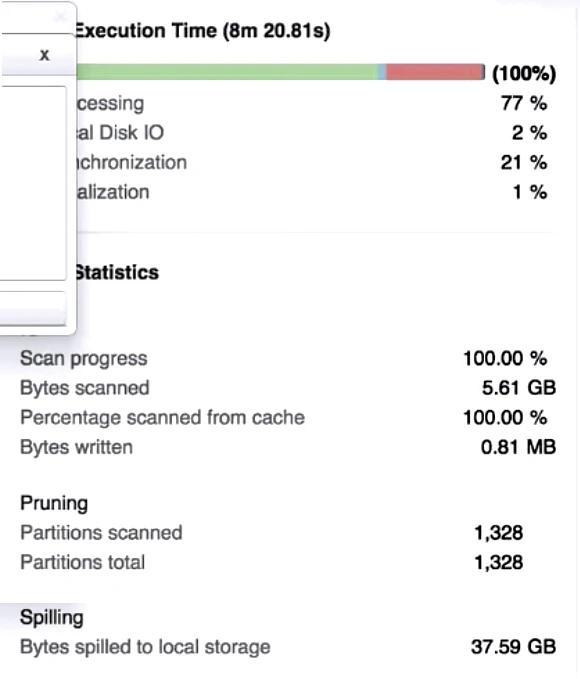
What step should the Engineer take to increase the query performance?
Here you have the best Snowflake SnowPro Advanced Data Engineer practice exam questions
A Data Engineer is investigating a query that is taking a long time to return. The Query Profile shows the following:
What step should the Engineer take to increase the query performance?
How can the following relational data be transformed into semi-structured data using the LEAST amount of operational overhead?

A Data Engineer executes a complex query and wants to make use of Snowflake’s query results caching capabilities to reuse the results.
Which conditions must be met? (Choose three.)
A Data Engineer needs to load JSON output from some software into Snowflake using Snowpipe.
Which recommendations apply to this scenario? (Choose three.)
Given the table SALES which has a clustering key of column CLOSED_DATE, which table function will return the average clustering depth for the SALES_REPRESENTATIVE column for the North American region?
Unlock the full Snowflake SnowPro Advanced Data Engineer question bank
Single payment · No subscription · No hidden fees
Standard
Quick preparation
30 days access
Premium
Guaranteed success
90 days access
Printable PDF download
NewSave every question as a PDF for offline study or printing.
100% Money Back Guarantee
Don't pass? Full refund.
Based on 6,968+ reviews
Join certified professionals who passed their exams with Examice
Examice helped me pass my AWS certification on the first try! The questions were incredibly similar to the real exam. Comments helped me understand answers I was struggling with.
Great results in a short prep time. Passed on my first attempt.
I needed to pass an exam for work, and this website delivered. The quality for the price is outstanding, and the support is really good. I passed without issues.
Skeptical at first, but impressed. Every question included clear, detailed explanations.
The guarantee gave me confidence to invest in the premium package. Turns out I didn't need it. Passed comfortably. The explanations for each answer were incredibly detailed and helped me grasp security concepts that I'd been struggling with for months.
Used Examice for my PMP certification. The questions were well structured and covered all exam domains thoroughly.
After failing my first attempt with other study materials, I switched to Examice and passed confidently on my second attempt.
The premium package was worth it. 90 days of access gave me the flexibility to study when it worked for me, without feeling rushed.
Straightforward questions that matched the real exam perfectly. Studied for two weeks and passed with a great score.
Everything you need to know. Contact us for more.
Our Snowflake SnowPro Advanced Data Engineer questions are based on real exam experiences and are continuously updated to match the current exam format. Most candidates who study with us report passing on their first attempt, based on a self reported post exam survey.
With our Premium package, you get a 100% money back guarantee. If you don't pass your exam after studying with our materials, simply contact us with your exam results and we'll refund your purchase. Terms and conditions apply, read our full refund policy to learn more.
Our question bank is updated regularly based on feedback from recent exam takers. We typically review and update our content every week with reports about new questions or changes to the exam format.
Yes. When your access is close to expiring, you can renew it for another 30 days directly from the exam page. If you need more time while you are still preparing, reach out and we will help.
This is a single payment with no recurring charges. Once you purchase, you get full access to all exam questions for the duration of your package (30 days for Standard, 90 days for Premium). No hidden fees or automatic renewals.
All 162questions · Detailed explanations · Printable PDF · 90 days access
single payment