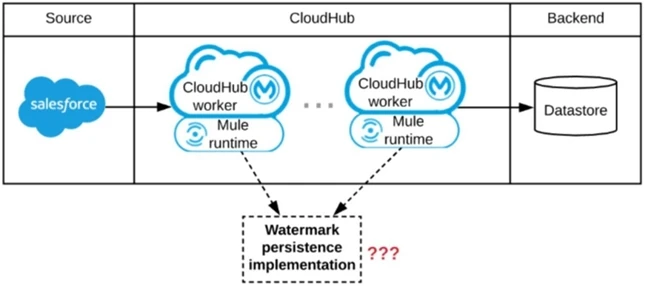
Refer to the exhibit. A Mule application is being designed to be deployed to several CloudHub workers. The Mule application's integration logic is to replicate changed Accounts from Salesforce to a backend system every 5 minutes.
A watermark will be used to only retrieve those Salesforce Accounts that have been modified since the last time the integration logic ran.
What is the MOST appropriate way to implement persistence for the watermark in order to support the required data replication integration logic?