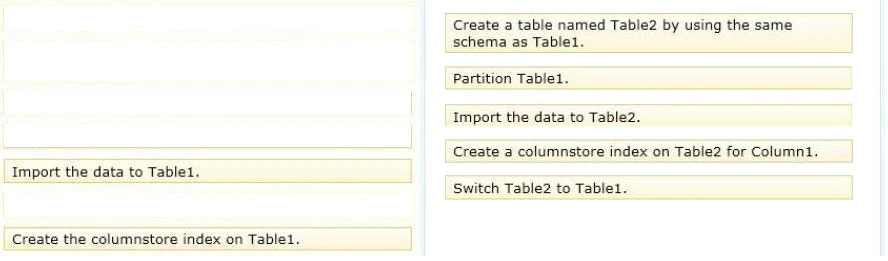
Box 1: Create a table named Table2 by using the same schema as Table1.
Note: Table2 is the staging table.
Box 2: Partition Table1 -
Box 3: Import the data to Table2.
Box 4: Create a columnstore index on Table2 for Column1.
Box 5: Switch Table2 to Table1 -
Note:
* An xVelocity memory optimized columnstore index, groups and stores data for each column and then joins all the columns to complete the whole index.
Columnstore indexes can transform the data warehousing experience for users by enabling faster performance for common data warehousing queries such as filtering, aggregating, grouping, and star-join queries.
* Tables that have a columnstore index cannot be updated.
There are three ways to work around this problem.
A) To update a table with a columnstore index, drop the columnstore index, perform any required INSERT, DELETE, UPDATE, or MERGE operations, and then rebuild the columnstore index. B) (applies in this scenario) Partition the table and switch partitions. For a bulk insert, insert data into a staging table, build a columnstore index on the staging table, and then switch the staging table into an empty partition. For other updates, switch a partition out of the main table into a staging table, disable or drop the columnstore index on the staging table, perform the update operations, rebuild or re-create the columnstore index on the staging table, and then switch the staging table back into the main table.
C) Place static data into a main table with a columnstore index, and put new data and recent data likely to change, into a separate table with the same schema that does not have a columnstore index.
Reference: Best Practices: Updating Data in a Columnstore Index