You are designing a fact table named FactPurchase in an Azure Synapse Analytics dedicated SQL pool. The table contains purchases from suppliers for a retail store. FactPurchase will contain the following columns.
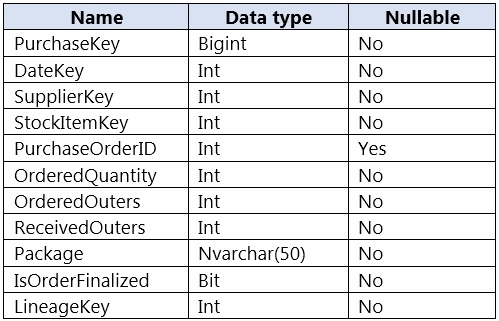
FactPurchase will have 1 million rows of data added daily and will contain three years of data.
Transact-SQL queries similar to the following query will be executed daily.
SELECT -
SupplierKey, StockItemKey, COUNT(*)
FROM FactPurchase -
WHERE DateKey >= 20210101 -
AND DateKey <= 20210131 -
GROUP By SupplierKey, StockItemKey
Which table distribution will minimize query times?