After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear in the review screen.
You are troubleshooting a slice in Microsoft Azure Data Factory for a dataset that has been in a waiting state for the last three days. The dataset should have been ready two days ago.
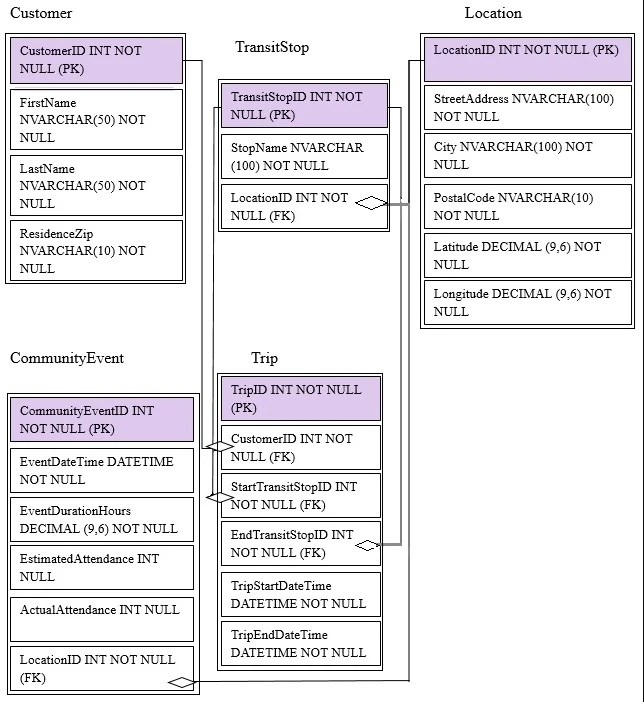
The dataset is being produced outside the scope of Azure Data Factory. The dataset is defined by using the following JSON code.

You need to modify the JSON code to ensure that the dataset is marked as ready whenever there is data in the data store.
Solution: You change the external attribute to true.
Does this meet the goal?