You need a build a solution to ingest real-time streaming data into a nonrelational distributed database.
What should you use to build the solution?
You plan to use queries that will filter the data by using the WHERE clause. The values of the columns will be known only while the data loads into a Hive table.
You need to decrease the query runtime.
What should you configure?
Which file formats can you use?
You plan to join a large table and a lookup table.
You need to minimize data transfers during the join operation.
What should you do?
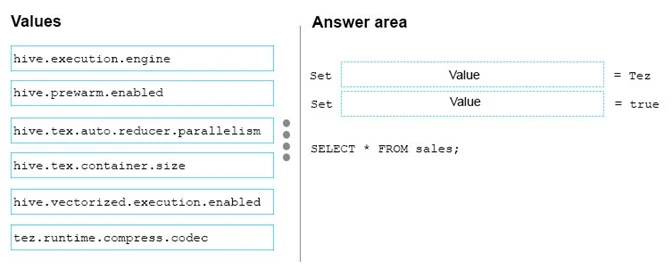
You have an Apache Hive cluster in Azure HDInsight.
You need to tune a Hive query to meet the following requirements:
✑ Use the Tez engine.
✑ Process 1,024 rows in a batch.
How should you complete the query? To answer, drag the appropriate values to the correct targets. Each value may be used once, more than once, or not at all.
You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
Select and Place: